
Domain-Driven Service Design with Context Mapper and MDSL
(Updated: )Reading time: 7 minutes
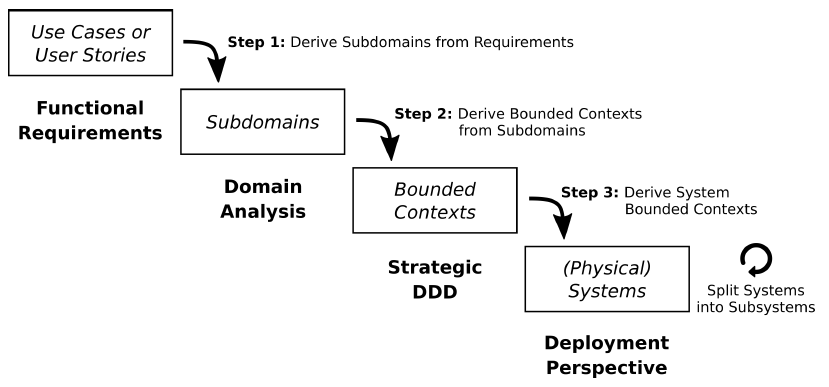
Content Outline
- Step 1: Elicit Functional Requirement(s)
- Step 2: Transform into Domain Analysis Model
- Step 3: Switch from Analysis to Design
- Step 4: Refine the High-Level Design
- Step 5: Advance to System Contexts
- Step 6: Generate MDSL Service Contracts (Abstract Port Level)
- Step 7: Turn Port-Level Service Contracts into Technology Adapters
- Wrap Up and Recap
In an ICWE keynote, I presented(ed) our evolving tool chain for object-oriented analysis and design (or DDD, to be precise) and service design. Here’s how to run the full demo. My conference slides that set the scene are here.
Note: This version of the post provides the essentials required to reproduce the demo steps. Motivation and conceptual background information is available in this article and this one.
Prerequisites: The instructions below assume that you have Context Mapper Version 6 (or higher) and MDSL Tools Version 5 installed.
Step 1: Elicit Functional Requirement(s)
Write a user story (or use case) in the Context Mapper DSL (CML), as explained in the Context Mapper documentation:
1
2
3
4
5
UserStory PaperArchiving {
As a "Researcher"
I want to create a "PaperItem" with its "title", "authors", "venue" in a "PaperCollection"
so that "other researchers can find and cite the referenced paper easily, and my h-index goes up."
}
Make sure that the file that you create has a .cml suffix so that the Context Mapper tools can recognize it.
Step 2: Transform into Domain Analysis Model
Transform the story from Step 1 into a domain PublicationManagement with a subdomain PaperArchive (that contains entities and services) as explained here by selecting the story and then “Context Mapper: Refactor->Derive Subdomain from User Requirements” from the pop up menu. The result should look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Domain PublicationManagement {
Subdomain PaperArchive {
domainVisionStatement "Aims at promoting the following benefit for a Researcher: other researchers can find and cite the referenced paper easily, and my h-index goes up."
Entity PaperItem {
String title
String authors
String venue
}
Entity PaperCollection {
- List<PaperItem> paperItemList
}
Service PaperArchivingService {
createPaperItem;
}
}
}
Note how incomplete the model is: all we know at this point is that some service realizes the story and that two related entities have a role to play. This analysis model captures what we know about the domain concepts from a user/domain expert point of view; it is not technical at all.
Step 3: Switch from Analysis to Design
Let’s apply some tactic and some strategic Domain-Driven Design (DDD) now, supported by a second Context Mapper transformation. Create a bounded context ReferenceManagementContext implementing the subdomain PaperArchive from Step 2 (select the subdomain, then “Context Mapper: Refactor->Derive Bounded Context from Subdomains”):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
BoundedContext ReferenceManagementContext implements PaperArchive {
domainVisionStatement "This Bounded Context realizes the following subdomains: PaperArchive"
type FEATURE
/* This Aggregate contains the entities and services of the 'PaperArchive' subdomain.
* TODO: You can now refactor the Aggregate, for example by using the 'Split Aggregate by Entities' architectural refactoring.
* TODO: Add attributes and operations to the entities.
* TODO: Add operations to the services.
* Find examples and further instructions on our website: https://contextmapper.org/docs/rapid-ooad/ */
Aggregate PaperArchiveAggregate {
Service PaperArchivingService {
String createPaperItem (@PaperItem paperItem);
}
Entity PaperItem {
String title
String authors
String venue
String paperItemId key
}
Entity PaperCollection {
String paperCollectionId key
- List<PaperItem> paperItemList
}
}
}
We have entered design mode, but still know very little about the realization (attributes, operations, etc.). Hence, the transformation converted the subdomain into a high-level bounded context of type FEATURE (explained here), but the generated code calls out some further TODOs.
According to this post, “a bounded context is a sub-system in a software architecture aligned to a part of your domain”. To quote the DDD crew again, “an aggregate is a lifecycle pattern originally described by Eric Evans. By aggregate, we understand a graph of objects that is a consistency boundary for our domain policies. Depending on the design of the aggregate we can either enforce them (make them invariant) or be forced to have corrective policies in place. Because of that it is important to design the boundaries of aggregates well, as they impact behaviours modelled within our domain.”
Step 4: Refine the High-Level Design
Next up is one of the few manual activities in this demo: The high-level design from Step 3 has to be detailed and improved as suggested by the TODOs. For instance:
- The signature of the
createPaperItemoperation that was created in the previous step can be improved. - Additional service operations for lookup
lookupPapersFromAuthorand format conversionconvertToMarkdownForWebsitecan be introduced in thePaperArchiveAggregate. - Value objects for the
paperItemIdand thepaperCollectionIdcan be specified (Context Mapper offers a a quick fix for this).
The result of this activity may look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
BoundedContext ReferenceManagementContext implements PaperArchive {
domainVisionStatement "This Bounded Context realizes the following subdomains: PaperArchive"
type APPLICATION
/* This Aggregate contains the entities and services of the 'PaperArchive' subdomain.
* TODO: You can now refactor the Aggregate, for example by using the 'Split Aggregate by Entities' architectural refactoring.
* [x] TODO: Add attributes and operations to the entities.
* [x] TODO: Add operations to the services.
* Find examples and further instructions on our website: https://contextmapper.org/docs/rapid-ooad/ */
Aggregate PaperArchiveAggregate {
Service PaperArchivingService {
@PaperItem createPaperItem (@PaperItem paperItem); // improved
Set<@PaperItem>lookupPapersFromAuthor(String who); // added
String convertToMarkdownForWebsite(@PaperItemId id); // added
}
Entity PaperItem {
String title
String authors
String venue
- PaperItemId paperItemId
}
ValueObject PaperItemId {
Long paperItemId
}
Entity PaperCollection {
- PaperCollectionId paperCollectionId
- List<PaperItem> paperItemList
}
ValueObject PaperCollectionId {
Long paperCollectionId
}
}
}
The [x] mark the completed TODOs. The refinement of the design is indicated by new context type APPLICATION.
Step 4a (optional): Generate JHipster Application Prototype
JHipster is an application generator that receives its data entity/domain model configuration via a JHipster Domain Language (JDL) file.
This tutorial on the Context Mapper website shows how to create JDL from design models captured in the Context Mapper DSL (please make sure that you use the latest version of the JDL template). Call the output file ReferenceManagementContext.jdl (it will be created in the src-gen folder).
A subset of the generated output is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/* Bounded Context ReferenceManagementContext */
entity PaperItem {
title String
authors String
venue String
}
entity PaperCollection {
paperCollectionId Integer
}
entity PaperItemID {
doi String
}
entity PaperCollectionId {
id String
}
microservice PaperItem, PaperCollection, PaperItemID with ReferenceManagementContext
/* relationships */
relationship OneToMany {
PaperCollection{paperItemList} to PaperItem
}
relationship OneToOne {
PaperItem{paperItemId} to PaperItemID
PaperCollection{paperCollectionId} to PaperCollectionId
}
The full file ReferenceManagementContext.jdl also has two application configurations including port numbers and technology choices. You might want to switch the application from 8081 to another port, for instance 8082.
Once you generated the JDL file, you can generate the application by running JHipster:
1
jhipster import-jdl ReferenceManagementContext.jdl
If you follow the Context Mapper instructions from here, you end up with a running microservice architecture (powered by JHipster, Spring Boot, React, including a gateway and a registry) that supports create, read, update, and delete operations on the entities (in MAP terms, these are exposed as Information Holder Resources), and also has a basic frontend:
- Find and start a service registry (by downloading it or cloning it).
- Build and start the Reference Management Context service (or application backend) with
mvnw(in its directory). - Build and start the gateway (or front end) with
mvnw(in its directory).
The application stub is available at http://localhost:8080/ when all its parts have been started successfully; the registry is at http://localhost:8761/.
Step 4b (optional): Deploy Application Prototype to PaaS Cloud
The microservices in the JDL (or a monolithic variant of them) can even be deployed to platform-as-a-service cloud providers such as Heroku. JHipster-to-Heroku deployment instructions can be found here:
1
jhipster heroku
Note 1: Since the application receives a URI (which has to be globally unique), you probably will have to change the application name in the JDL file. Heroku will not be able to build and launch the application if there are naming conflicts with other deployments.
Note 2: The default application configuration in the above JDL only works with validated Heroku accounts; adding prodDatabaseType postgresql to the application definition in the JDL file increases your chances for a successful build because the PostgreSQL add-on is part of the free tier at Heroku (at the time of writing).
When updating the application, run:
1
git push heroku master
Step 5: Advance to System Contexts
The Step 3 and 4 contexts reside on a logical feature and application level of abstraction. We can now take a more physical, or integration-oriented, view on the design and create frontend and backend/service layer contexts of type SYSTEM; call them ReferenceManagementFrontend and ReferenceManagementService. The third analysis and design transformation in Context Mapper does so (select the bounded context from Step 3, then “Context Mapper: Refactor->Derive Frontend and Backend Contexts”):
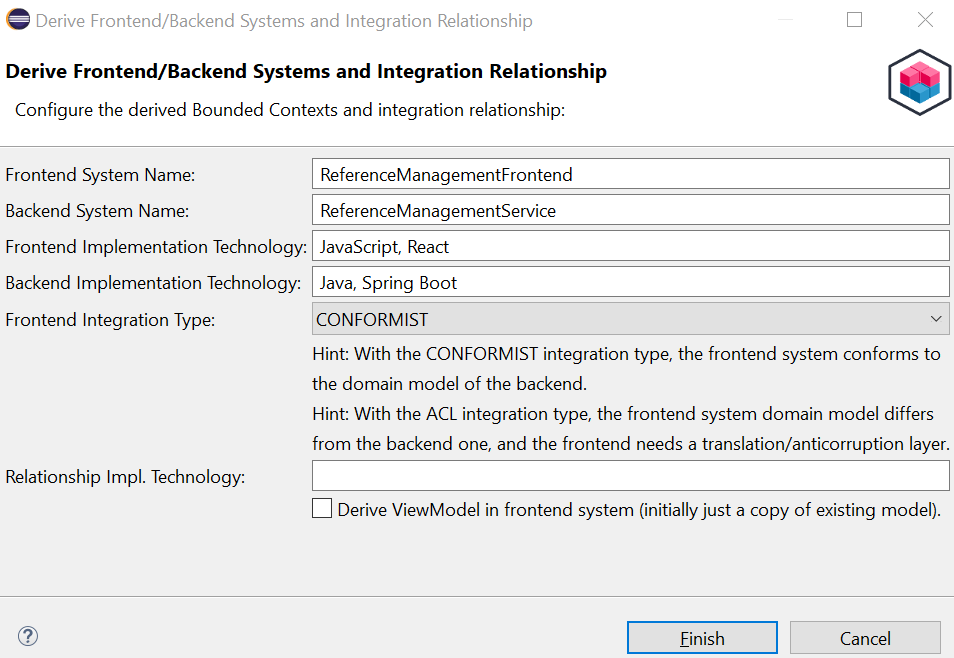
We end up with a lower-level design model and a context map with an exposed aggregate, available for download here.
In the new backend service context ReferenceManagementService, you might want to rename the single aggregate from PaperArchiveAggregateBackend to PaperArchiveFacade (just to make the output of the next steps look a bit nicer). Use the “Rename Element” refactoring in Context Mapper to do so consistently in one step. Do the same to rename:
PaperItemBackendtoPaperItemDTOPaperItemIDBackendtoPaperItemKeyand (optionally)PaperCollectionIDBackendtoPaperCollectionKey
We can decorate the aggregates and their operations (in entities and service) with responsibility patterns from MAP if we want:
- Add the
"INFORMATION_HOLDER_RESOURCE"decorator for this pattern in front of the aggregatePaperArchiveFacade. - Add
"STATE_CREATION_OPERATION"(pattern) before@PaperItemKey createPaperItem (@PaperItemDTO paperItem). - Add
"RETRIEVAL_OPERATION"(pattern) beforeSet<@PaperItemDTO> lookupPapersFromAuthor (String who);.
The result should look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
ContextMap {
contains ReferenceManagementFrontend
contains ReferenceManagementService
ReferenceManagementService [ PL ] -> [ CF ] ReferenceManagementFrontend {
implementationTechnology "HTTP"
exposedAggregates PaperArchiveFacade
}
}
BoundedContext ReferenceManagementService implements PaperArchive {
domainVisionStatement "This Bounded Context realizes the following subdomains: PaperArchive"
type SYSTEM
implementationTechnology "Java, Spring Boot"
"INFORMATION_HOLDER_RESOURCE" Aggregate PaperArchiveFacade {
Service PaperArchivingService {
"STATE_CREATION_OPERATION" @PaperItemDTO createPaperItem (@PaperItemDTO paperItem);
"RETRIEVAL_OPERATION" Set<@PaperItemDTO> lookupPapersFromAuthor (String who);
String convertToMarkdownForWebsite (@PaperItemKey id);
}
Entity PaperItemDTO {
String title
String authors
String venue
- PaperItemKey paperItemId
}
Entity PaperCollectionBackend {
int paperCollectionId
- List<PaperItemDTO> paperItemList
}
ValueObject PaperItemKey {
String doi
}
ValueObject PaperCollectionKey {
String id
}
}
}
All demo files created or generated up to here are available for download.
Note: Many more architectural decisions would be required now if this was a real-world design and not a tool demo. Some of the important ones are called out here.
Step 6: Generate MDSL Service Contracts (Abstract Port Level)
Microservice-Domain Specific Language (MDSL) is an Interface Description Language (IDL) that:
- allows describing API and service contracts but is not tightly coupled to HTTP,
- supports incremental modeling (because it tolerates ambiguities and gaps in early draft specifications), and
- features Microservice API Patterns (MAP) as first-class language concepts (for instance, the role and responsibility annotations we added in Step 5).
Instructions for transforming a CML model into MDSL can be found here. Note that at least one upstream context has to expose an aggregate (which must have a root entity or a service that exposes an operation). Our Step 5 model does so. The MDSL is generated into the src-gen folder of your Context Mapper project (language reference: endpoint types, data types):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
API description ReferenceManagementServiceAPI
data type PaperItemDTO { "title":D<string>, "authors":D<string>, "venue":D<string>, "paperItemId":PaperItemKey }
data type PaperItemKey { "doi":D<string> }
endpoint type PaperArchiveFacade
serves as INFORMATION_HOLDER_RESOURCE
exposes
operation createPaperItem
with responsibility STATE_CREATION_OPERATION
expecting
payload PaperItemDTO
delivering
payload PaperItemKey
operation lookupPapersFromAuthor
with responsibility RETRIEVAL_OPERATION
expecting
payload D<string>
delivering
payload PaperItemDTO*
operation convertToMarkdownForWebsite
expecting
payload PaperItemKey
delivering
payload D<string>
One MDSL specification per bounded context is generated, whose aggregates are modeled as endpoint types. The operations are transformed into, well, operations. The complete resulting API description can be found here.
Step 7: Turn Port-Level Service Contracts into Technology Adapters
Step 7a: Convert MDSL to Open API Specification (OAS)
In the MDSL plugin, select the MDSL file from Step 6 (or open it). Choose “MDSL->Generate OpenAPI Specification” from the context menu that pops up.
A YAML file is generated (again into the src-gen folder):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
openapi: 3.0.1
info:
title: ReferenceManagementServiceAPI
version: "1.0"
servers: []
tags:
- name: PaperArchiveFacade
externalDocs:
description: The role of this endpoint is Information Holder Resource pattern
url: https://microservice-api-patterns.org/patterns/responsibility/endpointRoles/InformationHolderResource.html
paths:
/PaperArchiveFacade:
summary: general data-oriented endpoint
get:
tags:
- PaperArchiveFacade
summary: read only
description: This operation realizes the [Retrieval Operation](https://microservice-api-patterns.org/patterns/responsibility/operationResponsibilities/RetrievalOperation.html)
pattern.
operationId: lookupPapersFromAuthor
parameters:
- name: Parameter1
in: query
required: true
schema:
type: string
responses:
"200":
description: lookupPapersFromAuthor successful execution
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/PaperItemDTO'
put:
tags:
- PaperArchiveFacade
summary: write only
description: This operation realizes the [State Creation Operation](https://microservice-api-patterns.org/patterns/responsibility/operationResponsibilities/StateCreationOperation.html)
pattern.
operationId: createPaperItem
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/PaperItemDTO'
responses:
"200":
description: createPaperItem successful execution
content:
application/json:
schema:
$ref: '#/components/schemas/PaperItemKey'
post:
tags:
- PaperArchiveFacade
description: unspecified operation responsibility
operationId: convertToMarkdownForWebsite
parameters: []
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/PaperItemKey'
responses:
"200":
description: convertToMarkdownForWebsite successful execution
content:
application/json:
schema:
type: object
properties:
anonymous1:
type: string
components:
schemas:
PaperItemDTO:
type: object
properties:
title:
type: string
authors:
type: string
venue:
type: string
paperitemId:
$ref: '#/components/schemas/PaperItemKey'
PaperItemKey:
type: object
properties:
id:
type: string
Load this OAS file into an Open API tool, for instance the online Swagger editor, to see whether this platform-specific API description and technical service contract validates.
If you are unhappy with the default output, work with the HTTP binding section in the provider part of MDSL to improve the endpoint-to-resource and operation-to-verb mappings according to the principles of REST. Run the MDSL-to-Open API generator again to pick up the new binding; it is documented here.
Step 7b (optional): Generate Other IDLs and Java Modulith
MDSL 5 supports several other output formats (following the principle of “polyglot integration”):
- gRPC Protocols Buffers
- GraphQL schema language
- Jolie, which in turn yields WSDL and XML Schema
- Java POJO “modulith” including client server stubs and unit tests ready to be executed (with some very simple sample data)
These generators are invoked in the same ways as the OAS one. The MDSL Tools: Users Guide provides usage instructions and mapping information.
All demo output up to here can be downloaded here.
Step 7c (optional): Use Open API Specification (OAS) to Update JHipster Application
JHipster supports API-First development which allows you to generate code with the above OAS file as input. In case you already generated a JHipster application in Step 4a, you can easily enhance it with the Open API Specification generated from MDSL now. It already includes an api.yml file in the src/main/resources/swagger directory: Enhance the application stub by integrating the content of the OAS file from Step 7 above into the already existing api.yml file (to be precise: the content under
tags, paths and under components has to be replaced with the output of Step 7a).
Note: You have to merge the two OpenAPI files manually for the time being, the one from Step 7a and the one generated by JHipster, since the security part of the api.yml is required by JHipster (don’t delete it!). The result of the merger is here.
Note: JHipster microservices must use JWT as security scheme; API-First monoliths can use HTTP basic authentication instead. Security cannot be turned off, even in development settings (or at least I did not find out how to disable it).
Let JHipster create a Spring MVC REST configuration and service interfaces from it:
1
./mvnw generate-sources (or mvnw generate-sources)
The generated application now contains the entities and relations from your JDL file (domain and data access/data source layer) as well as the endpoints and operations from the OAS in the generated sources (service/presentation layer).
Following the instructions for API-First development, you can now complete the operations by implementing the generated “Delegate” interfaces:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class PaperArchiveFacadeImpl implements PaperArchiveFacadeApiDelegate {
@Override
public ResponseEntity<InlineResponse200> convertToMarkdownForWebsite(PaperItemKey paperItemKey) {
// TODO: your implementation
return null;
}
@Override
public ResponseEntity<PaperItemDTO> createPaperItem(PaperItemDTO createPaperItemParameter) {
// TODO: your implementation
return null;
}
@Override
public ResponseEntity<List<PaperItemDTO>> lookupPapersFromAuthor(String parameter1) {
// TODO: your implementation
return null;
}
}
A simple implementation resolving the TODOs in the above code snippet can be found here.
Build and start the three components of the microservices architecture:
- JHipster/Eureka service registry (see Step 4a for instructions).
- Reference Management Context microservice, with
mvnwon the command line in the directory in which you created it (here: “ReferenceManagementContext”). - Frontend/gateway (in “gateway” folder), also with
mvnw.
Test with the Swagger test tools embedded in the application (e.g., http://localhost:8084/admin/docs, depending on the port number of the gateway, defined in the JDL file from Step 4a).
- Note: In the top right, make sure to select the correct “definition”, here: “referencemanagementcontext”.
- Find the “PaperArchiveFacade” resource path.
- Select an operation and click on “Try it out”. Set the required parameters, click on “Execute” and look at the “Server response”. Does it contain the expected data under (coming from the service implementation)? How about the HTTP status code?
Congratulations! We went all the way from a business requirements to an early, layered architectural prototype via domain-driven service design.
Wrap Up and Recap
Done! Here are some questions you might be able to answer once you have run though the above steps:
- How did the MDSL facade endpoint get mapped to Open API, gRPC, GraphQL, Jolie, Java?
- How were the service operations with their request and response messages mapped to HTTP verbs and JSON (and why)? What do the other generators do with them?
- Where do the MAP pattern links on endpoint and operation level (in the OpenAPI specification) come from?
- What happened to the data types used in request and response messages?
- Is there anything else worth mentioning (or missing)?
This post demonstrated how to progress from requirement elicitation/analysis to domain-driven design and contract-first service design in a few incremental steps, most of which tool supported (Context Mapper, MDSL editor). The hard work that will (and, imho, should) remain a human activity is the manual design Step 4 (and the optional MAP decoration of the DDD/CML output). The transformations and code generation steps demonstrate and educate us about the required steps and automate some of the repetitive boring tasks (“glue coding”, “plumbing” — so that you can focus on the design and, eventually, implementation work on the business logic/domain layer (rather than integration coding).1
Really Done?
Well, not quite, the seven steps only yielded an early prototype not doing that much. Next up are:
- Write client and server stubs, or let tools such as the Swagger ones (or API-First in JHipster) generate them.
- Implement real business logic, for instance to connect the service layer facade with the persistence and data access layer in the JHipster backend from Step 4a.
- Write your own frontend that replaces the JHipster one from Step 4a.
- Integrate via message-oriented middleware instead of HTTP (requiring AsyncAPI, which can be generated with an experimental AsyncMDSL extension).
- Deploy to a cloud, for instance platform-as-a-service offerings such as Heroku.
- Apply more microservice infrastructure patterns such as API Gateway, load balancers, etc.
- Go back to analysis and design: iterate over the design; add
Teamcontext(s), define more user stories (or use cases) and owners of system BCs, and/or refactor the CML model continuously. For instance, apply tactic DDD patterns such as Repository, Factory, Service in addition to Aggregate, Entity and Value Object to craft a rich Domain Model.
The list goes on. Service and application design, implementation and integration might be business as usual, but never gets boring! Our new Design Practice Repository (DPR) can guide you through through the more advanced tasks.
Comments? Suggestions? Need help? Contact us (see links below).
– Olaf (a.k.a. socadk)
PS: A slightly shorter version of this post is now available on Medium.
Team Acknowledgements
This toolchain and demo would not exist without Stefan Kapferer and Mirko Stocker at HSR/OST IFS(https://www.ost.ch/de/forschung-und-dienstleistungen/informatik/ifs-institut-fuer-software) and the MAP team. Thank you guys!
The figure at the top of the figure was first published in Kapferer, S.; Zimmermann, O.: Domain-Driven Architecture Modeling and Rapid Prototyping with Context Mapper, Selected extended papers from Model-Driven Engineering and Software Development, Springer CCIS Volume 1361 (PDF).
-
Ain’t this cool? You might not want use such tool chain in everyday forward engineering all the time, but hopefully you find it educational and can make good use of it in prototyping and when mocking or trying out service designs. ↩