
Novel Measurements for Academic Work (and Beyond?)
(Updated: )Reading time: 12 minutes

Content Outline
I enjoyed reading about “Satirical ways to measure academics” in Austin Z. Henley’s blog. It inspired me to compile additional ones — about teaching, research, administration of academic work and, more generally, meetings and communication.
My collection got more comprehensive than expected:
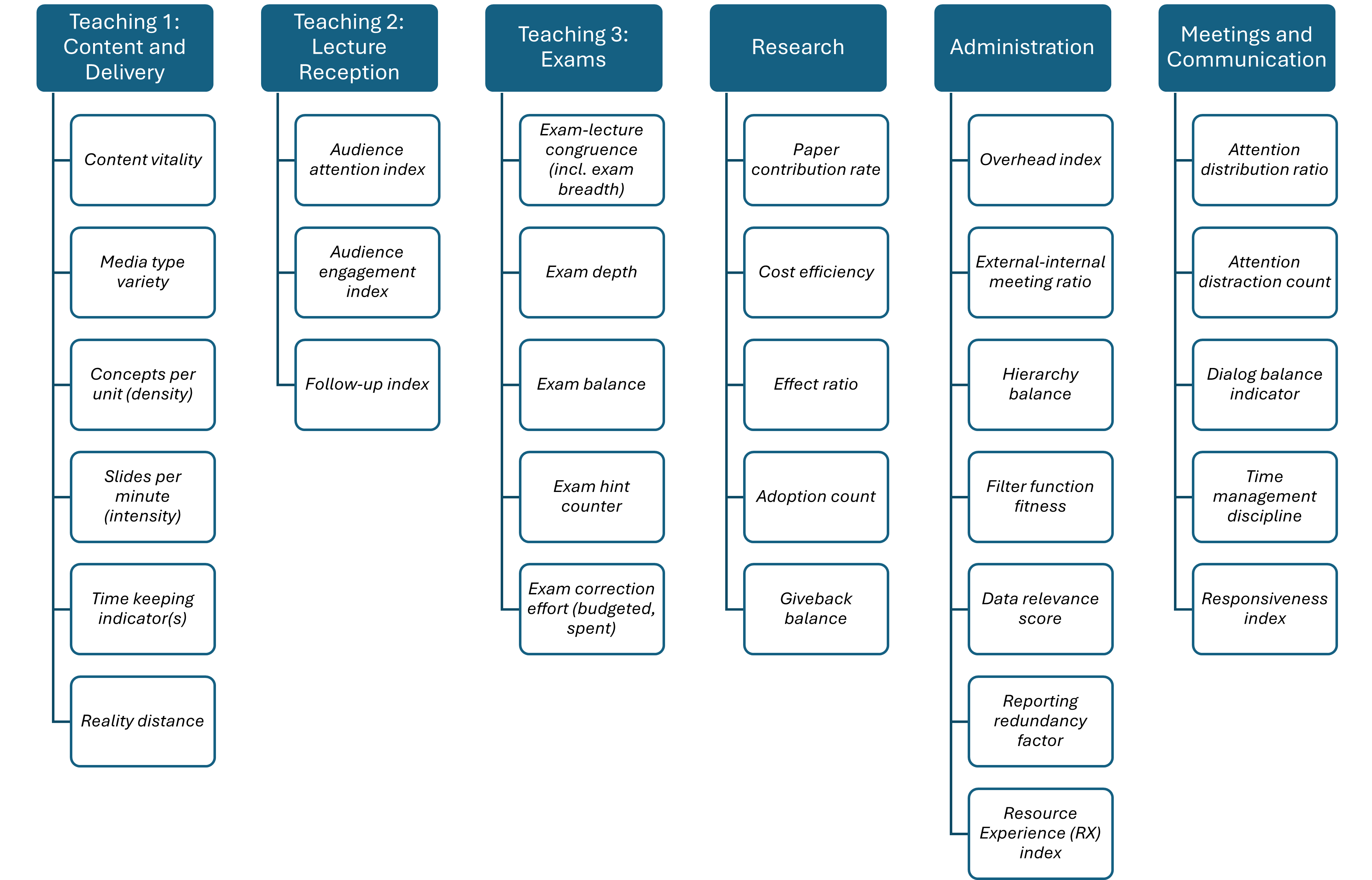
Feel free to jump to the section of most interest to you!
Teaching
Let’s start with preparing and giving lectures, one of the key roles and responsibilities of professors and other staff members in universities:
- Content vitality. Average number of slides (or other presentation unit) updated in last three years divided by total number of slides. Can be calculated per weekly lesson or for entire courses and lecture terms. Fixing typos or broken links counts, reordering or hiding slides does not. 😉 Note that the score for well-established lectures on timeless topics such as introduction to programming or automata theory will differ from lectures not taught before that cover fast-moving topics such as cloud-native application design or generative Artificial Intelligence (AI).1
- Media type variety. Percentage of slides with figures, animations or interactive elements vs. those with text or tables. Text-only slides have a bad reputation. However, figure-only slides without explanations will not serve students well who could not attend the lecture, for instance because they study and work part time. Words complementing figures also help attendees to recapitulate.2 Is 50-50 a healthy mix? Or 60-40? 70-30?
- Concepts per unit (density). Each slide should cover one and only one topic or concept. Slides loaded with words usually do not work well while presenting; hence, it makes sense to keep an eye on the words per slide. The number of fonts and font sizes used can be measured too; 10pt or less indicates a design smell. A related metric could be the maximum depth of item lists; three or more levels are difficult to comprehend.3 Figures also have a density; the number of figure elements (e.g., components and connectors in architecture diagrams) can be counted as a first indicator.
- Slides per minute (intensity). The style of the lecture material influences which value is adequate for this metric (see media type variety). It has a mutual dependency with the text/figure densities (concepts-per-unit metric). Spending 20 minutes or more on a single diagram such as a flow chart or a component diagram, possibly animated, does not have to be bad — if the time keeping indicators (next metric) does not suffer.
- Time keeping indicator(s). How about a) number of slides shown (and covered in depth) divided by number of slides prepared and/or appearing in handout, b) number of times presentation jumps back and forth because lecturer is looking for a particular slide, c) number of times the lecture runs over to make it through all slides relevant for the exam. Try to get down to zero, everybody needs breaks!
- Reality distance. This measure also is lecture topic depending. How about counting:
- The number of recent grey literature covered, the number of industry talks attended and then used as input for course preparation and the number of guest lectures from professionals (e.g., software engineers) from industry.
- The average number of trending topics and buzzwords a) taken into consideration for future lectures, b) included in next edition of lecture because they fit (w.r.t learning objectives; see content vitality metric), c) filtered out for good reasons (e.g., hyped but not expected to last, lack of maturity). How about a 10-2-8 rule of thumb?
Not all of these suggestions will be easy to measure. For instance, a word count feature is available in many text processors and editors, but not necessarily in presentation software; a PDF export may serve as an intermediary.
Let’s switch from content creation to lecture reception measures:
- Audience attention index. Lecturing is a form of communication, and communication channels have at least two endpoints, message producer and consumer.4 Not every message sent is actually received. Measured 15, 30, 45 and 60 minutes into the lecture, index elements could be:
- Number of students actively listening divided by number of students attending.
- Subset of students that not only listens but also takes notes.
- Number of students working on Git pull requests, completing assignments in other lectures, or being absorbed by social media feeds. 😉
- Audience engagement index. I can think of several related scores:
- Number of students attending vs. number of students enrolled.
- Number of lecturer questions asked and answered by students. Note that it takes students some time to realize that a question has been asked, think about an answer and offer it in class (for evidence, see this article).
- Number of questions asked by students and answered by lecturer. Redirecting answers such as “I explained this two minutes ago, are you following?”, “I’ll give you an answer later” and “what do the other participant in class think?” do not count for this metric (but could become a separate one).
- Follow-up index. How about the following three elements:
- Percentage of students postprocessing lecture material and their notes shortly after a lecture has taken place. Note that the exam period is not meant by “shortly”.
- Percentage of students participating in voluntary exercises.
- Number of students checking learning progress by answering repetition questions shortly after the lecture (assuming that such questions have been handed out).
Finally, it is exam time:
- Exam-lecture congruence. Two measurable indicators could be a) exam breadth, the portion of topics taught in lecture and practiced in exercises that is actually examined, b) secondary literature counter, the number of books and other non-lecture resources required to prepare for exam and pass it and c) exam anomalies. Hopefully, none of the exam questions asks about topics not covered or only touched upon due to timing issues.
- Exam depth. Amount of learning levels examined; each level requires a different type of question or assignment. The examined levels should match those of the learning objectives for the course/class.
- Exam balance. The distribution among the learning levels influences how difficult an exam is, assuming that tasks on all examined levels have been exercised. Unbalanced exams, possibly lacking breadth but going deep in unexpected ways (see next metric, exam hint counter) tend to be less fair than balanced ones.
- Exam hint counter. Number of tips given minus number of default “yes, in scope, just like everything else I say and hand out” answers to student question “is this topic relevant for the exam?”. Tips should help prepare, but not allow to pass without an acceptable understanding of the taught subjects. A positive value will be appreciated; how about 1-2 hints per 90-minute lesson?
- Exam correction effort (budgeted vs. spent). Time planned and compensated versus time actually spent. Can be calculated per exam and student or per exam/lecture edition. A low number might indicate experience and efficiency, but also a lack of dedication and rigor (or commitment to quality and fairness). Assumptions: the exam is not a digital one and its correction is not delegated; if so, adjustments are required.
How about existence of a script? This would be a binary metric. Actually, maybe three values make sense for it: yes, no, planned (but haven’t found the time to write it yet). 😉
Research
The section “Goal and measurement differences” in this post reports existing incentive systems and current metrics.
How about the following additional ones:
- Paper contribution rate. Indicators for the individual contribution per author and paper could be a) number of sections/pages written divided by total number of sections/pages, b) same for reviewing (rather than mere acclaiming or approving passively). Can be measured per paper or as an average value for a particular researcher. Note that it is also possible to contribute in other, less direct ways, for instance by developing prototypes or conducting experiments.
- Cost efficiency. Number of papers written and published divided by amount of funding granted (per project, per person). Not everybody will like this one! I added it for those of you not too lucky w.r.t. funding raising, but still doing great work, as in: relevant, novel and demonstrated to be technically sound.5
- Paper effect ratio. Total number of citations divided by number of papers written and published. I admit that I came up with this one to (hopefully) look good w.r.t. at least one metric. 😉
- Adoption count. Number of times a research paper is mentioned in the gray literature (blog posts, vendor white papers, etc.) plus number of prototypes transferred to industry sustainably (transferred and used for some time, that is). The more, the merrier; see posts about the gap between research and practice (and bridging/closing it) for a deeper discussion and tips. Open access publication may have an advantage over paywalled ones; see this post for tips to how advertise results.
- Giveback balance. Number of journal and conference papers reviewed divided by those submitted. Should be greater than 1; many 0s and 1s will let the peer review system collapse.
The average number of co-authors per paper per year could be interesting too; is a high number a sign of strong networking and teamwork or a sign of “tailgating”?6 Communities differ, a relative measure might be needed here, indicating deviations from community habits.
Please do not turn these suggestions into a bean-counting game! See Discussion section at the end of this post for rationale for this kind request.
Administration
It is all about flow, or effort vs. effect!
- Overhead index. Also known as value creation-housekeeping index. Time spent forecasting and coordinating vs. time spent delivering and disseminating technical results vs. time spent reporting status and performance. 5-90-5 or 10-80-10 are outstanding, 40-20-40 sounds like less fun but has been reported.
- External-internal meeting ratio. Number of meetings with clients (e.g., students, partner firms in industry) divided by internal meetings (with peers, faculty staff and management plus those with supporting functions such as human resources, procurement and legal). Talking to prospective students and future industry partners is an investment that is part of value creation.
- Hierarchy balance. Time spent with own management vs. time spent with peers vs. time spent meeting people reporting to oneself directly or indirectly. This networking and care-taking metric complements the overhead index (value creation-housekeeping ratio). The elevator metaphor that Gregor Hohpe established in the context of software architecture explains that both upstream and downstream meetings (or, more generally, interactions) are needed; finding an adequate ratio depends on the individual role and leadership style in place.
- Filter function fitness. Percentage of orders, rules etc. from upper management a) passed through, b) communicated downstream with additional comments and adjustments, c) handled on the management level without involving the managed teams. All three extremes probably indicate that something is not right.7 How about 20-40-40, with the additional comments and adjustments explaining why the communicated request is important and/or urgent and how to respond to it (e.g., giving an example)?
Over to reporting:
- Data relevance score. Impact of data reported on business development, strategies etc. Zero has been reported, full traceability from data to decisions causing change (and the mid- to long-term impact of these decisions) would be ideal.
- Reporting redundancy factor. Number of redundant requests to report the same data in a different format, on a different level of aggregation and granularity or at a different time (or all of that). Two is not too bad, values between four and five have been reported.
- Resource Experience (RX) index.8 Number of times the enterprise resource planning and controlling systems, expense reimbursement and time reporting tools in particular, are complained about per month: a) quiet sighs, in home office (assuming that the accounting systems can be reached from remote) and b) loud curses, with colleagues present. 😊
- Two to three sighs per months and a single public cry of frustration per month are tolerable, I’d say.
- I’ll let you decide on values that indicate “too much, let’s activate our user-centered design experts to improve the systems” for you and your organization.
The scores that indicate a lack of efficiency or breaking the flow of course were reported by members of my professional networks who never worked for the same organizations as I do/did… can’t happen here. 😉
Meetings and Communication
Expert organizations such as research groups, institutes and faculties tend to meet, for instance weekly, monthly or annually. Meetings have been identified as a primary flow breaker for developers.9 While academic lecturer/researcher productivity might not have been researched and surveyed yet, we may assume that similar observations would be made.
The previous section already suggested an external-internal meeting ratio metric, so let’s keep track of what happens in meetings:
- Attention distribution ratio. Percentage of time in meetings spent a) with laptop closed and smartphone put away (and silent), b) with laptop and/or smartphone used to contribute to meeting or look up meeting-related matters, c) with laptop and/or smartphone used to do email, code, play games, or watch cat videos. I would say that 80-20-0 is a decent score (in most cultures). How are you doing?10
- Attention distraction count. Number of active online chats with external people. Variant: number of chats with people attending the same meeting; the second channel might be about meeting topics or on something completely different. There is a tradeoff between responsiveness and personal efficiency on the one hand and group efficiency and ethical values such as respect (for speakers, for hosts and moderators, for active listeners) on the other hand.
- Dialog balance indicator. Speaking time divided by listening time. We are talking about meetings here, not about presentations. Numbers greater than 1 are not good most of the time (not even for the meeting host). Exceptionally high values might be a sign of missing empathy or soft skills.
- Time management discipline score. Number of times a recurring meeting runs over, which is not made explicit as its planned end comes near. Is “meeting runs over every time” a bad sign? Participants might get used to it and adjust their scheduled beforehand; “meeting runs over sometimes, but it is not predictable if and when” might be worse.
Finally, I propose the following metric for communication:
- Responsiveness index. Average time to respond to enquiries from stakeholders, those in the value chain particular (e.g., students and teaching assistants in the context of this post). Responses such as “I’ll respond later” (without saying when, without doing so), “Thank you for the question, I can’t help but also have a question for you” or “Not my business, you have to ask somebody else” do not count. 😉
See “Just send an email: Anti-patterns for email-centric organizations” eBook and the email antipatterns website by Cesare Pautasso for other examples of poor responses, as well as general advice how to improve correspondence.
Discussion
This post, first published on April 1 2025, is the result of a personal reflection, fed by anecdotal rather than empirical evidence. Inspired by the Model-View-Controller pattern, the post is meant to be engaging and entertaining in its presentation (view) and share what matters in its content (model); please decide for yourself whether the proposed metrics are just satirical or can actually be useful (controller). See the following discussion for suggested usage — and related warnings.
Summary. The post suggested 14+5+7+5=31 new metrics for academic work, teaching and research in particular. The metrics about administration, meetings and communication might also be interesting for other types of expert organizations.
Wait a minute… a total of 31 in a blog post from a computer scientist? 😮 Ok, so here is one more, a meta-metric (thanks Austin!):
- Improvement attempt counter. Number of times somebody tries to improve one of the metrics, whatever that person has decided to be a good target value for it. Hello (again), tradeoffs and real-world constraints!
32 ✔️
Goodhart’s Law and Availability Bias. None of the suggested metrics should become targets; Goodhart’s Law applies:
“When a measure becomes a target, it ceases to be a good measure”.
Some of the proposed metrics seem to conflict with the availability bias, stating that things are measured that are easy to measure. But even if some will be rather hard or even impossible to measure, their definitions hopefully do send a message anyway, a message of values, a message of what matters and what makes us effective and efficient (in my humble opinion). 😀
Handle with Care. If you choose to use the suggested metrics as intended, please do so with a grain of salt. Feel free to adjust.
Contexts, communities and their cultures are very diverse. As pointed out in the first sections, teaching subjects differ in their nature and their change dynamics; for instance, a low context vitality index might indicate stability and maturity rather than a lack of required updates. Research areas and their habits differ too.
Some administration, including planning and reporting, is and will always be required; it might even be mandated because external obligations have to be fulfilled. Some meeting topics might not be relevant for all participants, but still have to be covered. But it is good to be aware of the risk of overdoing and control one’s behavior when things get tedious or boring in meetings. Finally, belated or missing email responses might simply be caused by overload.
Following Goodhart’s Law, I do not recommend using any of the 32 metrics in this post to evaluate other people’s performance. But (hopefully) you can find inspiration in them to assess and improve yourself. Some of the footnotes in this post give or point at suggestions how to improve, and I cover hints about technical writing in other posts.
Which metrics would you suggest? How do you use metrics in general, do you align them with your values?
– Olaf, on April 1, 2025
Acknowledgements. Mirko Stocker, Stefan Kapferer and others contributed to earlier versions.
Notes.
-
The examples show that this post comes from somebody with a computer science background. Hopefully, the general messages behind the proposed metrics are applicable and useful in other fields too. ↩
-
Combining text with supporting graphical elements yields visual channels. ↩
-
Presentation styles and opinions about them vary. Many presenters ban bullet point sentences completely, at least for presented slides; supporting text then goes into a complementary infodeck or a background information section. ↩
-
Hopefully there are multiple consumers (at least most of the time). ↩
-
I did write “lucky” and not “successful” for a reason. 😉 ↩
-
Ski lift would be an alternative metaphor. ↩
-
I have heard quite interesting explanations for the pass through extreme (100-0-0) over the years. Agility was part of one of them. ↩
-
The R in RX stands for human resource (not a nice term but still common; with the R standing for researcher, we can stick to the RX acronym). ↩
-
For evidence, see this paper and this interview with Gail Murphy. ↩
-
Does your attention distribution rate differ from meeting to meeting? ↩